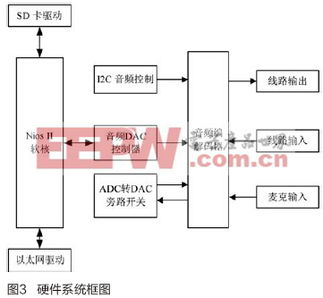
在能源管理与绿色发展的时代背景下,企业能耗在线监测系统已成为实现精细化管理、节能降耗、响应国家双碳战略的关键基础设施。一个成功的系统不仅依赖于精准的传感层与可靠的网络层,更离不开强大、高效、安全的数据处理与存储支持服务。本文将从系统规划与建设的角度,浅析数据处理与存储支持服务的核心作用、关键规划要点及建设路径。
一、 数据处理与存储服务的核心价值
数据处理与存储是能耗监测系统的“大脑”与“记忆中枢”。其核心价值体现在:
- 数据价值挖掘的基石:原始能耗数据(电、水、气、热等)通过采集网关汇聚后,需经清洗、校验、归一化等处理,转化为标准、可信的数据资产,为后续的分析、报表、预警与优化提供原料。
- 业务连续性的保障:稳定可靠的存储服务确保海量时序数据的持久化保存,支持历史追溯、同比环比分析、能效基准建立,是能源审计与碳核算的数据基础。
- 实时决策的支持:高效的数据处理能力(如流处理)能够对实时能耗数据进行快速计算与逻辑判断,即时触发越限报警、设备异常预警,助力生产调度与故障快速响应。
- 系统扩展与集成的关键:良好的数据处理架构与开放的存储接口,便于未来与MES(制造执行系统)、ERP(企业资源计划)或上级政府监管平台对接,实现数据共享与业务联动。
二、 系统规划阶段的关键考量
在项目规划初期,必须对数据处理与存储服务进行顶层设计:
- 数据架构规划:明确数据分层(如边缘处理层、实时库、历史库、分析库),定义各层的数据格式、粒度、保留周期及流转逻辑。通常采用“热-温-冷”数据分层存储策略以平衡性能与成本。
- 技术选型:
- 数据处理:根据实时性要求,选择批处理(用于日/月报表)与流处理(用于实时监控)相结合的技术栈,如采用Flink、Kafka Streams进行流计算,使用Spark进行复杂批分析。
- 数据存储:针对时序数据高并发写入、按时间范围查询的特性,优先选用时序数据库(如InfluxDB、TDengine、IoTDB)作为核心存储。关系型数据库(如MySQL、PostgreSQL)用于存储元数据、配置信息及聚合结果。对象存储可用于长期归档原始数据文件。
- 性能与容量规划:基于监测点数量、数据采集频率、每个数据包大小,估算日/年数据增量,并预留足够冗余,以此确定存储容量、计算资源及网络带宽需求。
- 安全与合规规划:设计数据加密(传输与静态)、访问权限控制、操作审计日志、备份与容灾方案,确保数据安全并满足行业及国家数据安全法规要求。
三、 建设实施路径建议
- 基础设施准备:部署稳定、可扩展的服务器或采用云服务(公有云、私有云或混合云),配置必要的虚拟化资源、网络与安全环境。
- 平台组件部署与集成:安装并配置选定的数据库、消息队列、流处理引擎等软件组件,打通从数据采集、消息中间件到处理存储的完整管道。
- 数据管道开发:开发数据接入、格式解析、数据清洗、质量校验、标准化转换以及向不同存储层分发的处理逻辑。确保数据流的稳定与高效。
- 服务接口开发:构建统一、标准化的数据服务API(如RESTful API),为上层应用(如Web看板、移动APP、分析模型)提供灵活、高效的数据查询与访问服务。
- 监控与运维体系建立:建立对数据处理作业健康度、存储系统性能(如IOPS、延迟、磁盘使用率)、数据流延迟的监控告警机制,并制定日常维护、备份与故障恢复预案。
四、 未来展望
随着物联网、大数据与人工智能技术的融合,未来的能耗数据处理与存储服务将更加智能化。例如,引入边缘计算在数据源头进行初步滤波与压缩以减轻中心压力;利用大数据平台进行更深入的能效模式挖掘与预测性分析;通过数据湖仓一体化架构,更灵活地支撑多维分析。因此,在规划与建设时,保持架构的开放性、模块化与可扩展性,将为未来技术演进与业务深化预留宝贵空间。
###
数据处理与存储支持服务是企业能耗在线监测系统稳定运行与价值发挥的“幕后英雄”。其规划需前瞻务实,建设需扎实稳健。只有构建起一个高效、可靠、安全且灵活的数据基础支撑平台,能耗数据才能真正从冰冷的数字转化为驱动企业节能增效、实现可持续发展的智慧能量。