每年618电商大促,对众多企业而言,不仅是销售业绩的狂欢,更是对后端技术系统,特别是存储体系的极限压力测试。海量订单、瞬时流量洪峰、数据实时读写,这些挑战让传统存储架构常常捉襟见肘。随着存储技术的迭代升级与专业化支持服务的完善,运维的难度正在显著降低。本文将深入探讨支撑618平稳运行背后的存储升级之路,以及“存储支持服务”如何成为保障业务连续性的关键一环。
一、 从“痛点”到“拐点”:存储升级的必然选择
在早期的电商大促中,存储层面常面临几大核心痛点:
- 性能瓶颈:集中式存储难以应对高并发读写,导致页面加载缓慢、交易卡顿甚至失败。
- 容量与弹性不足:预测流量困难,存储扩容周期长、成本高,无法快速响应突发需求。
- 可靠性风险:硬件故障、数据不一致等问题可能引发服务中断,造成巨大损失。
- 运维复杂:异构存储环境管理繁琐,故障定位难,对运维团队技能要求极高。
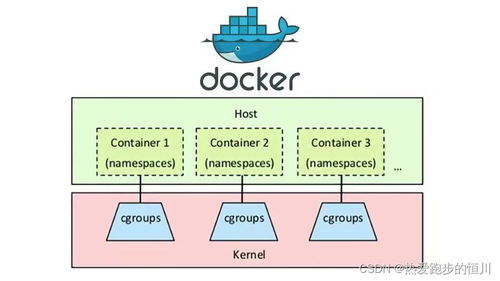
为解决这些问题,存储架构经历了从传统集中式SAN/NAS,到分布式存储,再到如今云原生存储与存算分离架构的演进。例如,采用全闪存阵列提升IOPS和延迟;利用分布式存储(如Ceph、自研分布式系统)实现横向扩展和更高可用性;通过容器存储接口(CSI)与Kubernetes深度集成,实现存储资源的敏捷供给与生命周期管理。
二、 618背后的存储升级关键技术
- 高性能全闪存与NVMe:为了处理支付、库存扣减等核心链路的微秒级延时要求,全闪存阵列与NVMe over Fabrics(NVMe-oF)协议成为标配,极大提升了存储介质与网络通道的效率。
- 分布式存储与弹性扩展:对象存储承载海量图片、视频等非结构化数据;分布式块和文件存储支撑数据库、中间件等,可根据流量预测自动弹性伸缩,实现“分钟级”扩容。
- 智能分层与数据生命周期管理:通过热、温、冷数据自动分层,将访问频繁的“热数据”置于高性能存储,将归档数据移至低成本存储,在保证体验的同时优化总体拥有成本(TCO)。
- 存储与计算分离:将存储资源池化,独立于计算节点进行扩展和管理。这使得计算节点可以无状态化,更易于弹性伸缩和故障恢复,是云原生架构的重要基石。
- 软件定义存储(SDS):通过软件抽象层管理异构硬件,提高了灵活性、自动化程度和资源利用率。
三、 “存储支持服务”:让运维化繁为简的核心保障
技术升级解决了架构问题,而将技术潜力转化为稳定生产力,则高度依赖于专业的存储支持服务。这不再仅仅是硬件维保,而是涵盖规划、实施、优化、运维的全栈式服务。
- 大促专项护航服务:在618前夕,服务团队会进行全面的健康检查、性能压测和容灾演练。制定详尽的应急预案,并安排专家全程值守,实时监控存储集群状态,秒级响应异常。
- 智能运维平台与可观测性:通过统一的监控平台,实现对存储性能、容量、健康度的全景可视。利用AIops能力进行智能预警、根因分析甚至自动修复,变“被动救火”为“主动预防”。
- 专家咨询与架构优化:服务提供商的经验丰富的架构师,能根据业务特点(如读多写少、海量小文件等)提供最佳实践和调优建议,帮助客户设计高可用、高性能的存储方案。
- 全生命周期管理:从选型规划、部署实施、日常运维到扩容升级、数据迁移乃至最终退役,提供一站式服务支持,让客户聚焦核心业务创新。
- 教育与知识转移:通过培训、文档和社区,提升客户自身团队的存储管理能力,构建长效的运维体系。
四、 未来展望:走向自动驾驶的智能存储
未来的存储系统将更加智能化、自动化。通过深度集成AI,存储可以实现:
- 自预测:基于历史数据与业务趋势,精准预测容量与性能需求,提前完成资源调配。
- 自优化:动态调整数据布局、QoS策略和压缩/去重策略,持续保持最佳性能与效率。
- 自修复:从硬件故障到软件异常,实现更高程度的自动隔离、恢复与数据重建。
届时,“存储支持服务”将更多地向策略制定、架构治理和异常处置等高级领域深化,而日常的运维管理工作将极大简化,真正实现“运维不再难”。
###
618的辉煌战绩,是前端商业创新与后端技术基石共同作用的结果。存储系统的升级演进,从解决性能、扩展性等基本问题,发展到与云原生、智能化深度融合。而专业、 proactive(主动式)的存储支持服务,正是确保这套复杂系统在关键时期稳定、高效运行的“定心丸”和“加速器”。这条路不仅是技术的升级之路,更是运维理念从繁重手工操作向智能高效服务转型的必由之路。